
RAGの検索を評価するranxを使ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
はじめまして、クラスメソッド株式会社 新規事業部のレオナです。
この記事では、RAG(Retrieval-Augmented Generation)の検索精度を評価するためにranxを使って定量的な分析を行います。
前回のブログでは、RAGの検索精度向上を目的にReRanking手法を適用し、検索結果のドキュメント順位が変わることを定性的に分析しました。前回の記事はこちら。しかし、検索精度を定量的に評価することはできていませんでした。
生成AIを使ったチャットボット
生成AIを用いたチャットボットは、ユーザーからの質問に対して関連する回答を提供するために設計されています。検索精度を向上させることで、より的確な回答を提供できるようになります。
RAGとは
RAGとは外部知識ベースからの検索(Retrieval)とLLMによる回答⽣成を組み合わせたフレームワークです。外部知識ベースから関連情報を検索することで、最新の情報に基づいた回答が可能になります。
RAGを実装する上での課題
RAGを実装する上でretrievalの重要なポイントとして、以下の必要な作業が挙げられます。
- 検索結果の精度向上
- モデルのパフォーマンス評価
前回のブログの振り返り
前回のブログでは、ReRanking手法を用いて検索結果の順位変化を定性的に分析しましたが、検索精度を定量的に評価することができていませんでした。今回のブログでは、この課題を解決するために「ranx」を使用して、検索精度を定量的に評価します。
今回のブログの目的
今回のブログの目的は、対象の埋め込みモデルを使用した際の検索精度を比較することです。そのために、RAGの検索精度を定量的に評価するためにranxを使用し、各モデルの性能を指標を用いて分析します。具体的には、Hit Rate、MRR(Mean Reciprocal Rank)、NDCG(Normalized Discounted Cumulative Gain)といった評価指標を用いて検索結果を定量的に評価し、比較します。
ranxとは
ranxとは検索ランキング評価用のライブラリです。検索システムのアルゴリズムやエンジンの評価に使えるPythonライブラリになっています。ranxでは、以下のような評価指標を算出することが可能です。
- 評価指数
今回はHit Rate、MRR、NDCGの評価指標を使用します。
Hit Rate(ヒット率)
- 定義:ユーザーが検索したとき、提供された結果の中に少なくとも1つ、ユーザーのクエリに関連する情報がある割合になります。
- 例:ユーザーが「東京の天気」と検索したとき、少なくとも1つの検索結果が東京の天気予報に関するものであれば、「ヒット」と数えます。
MRR(Mean Reciprocal Rank)
- 定義:ユーザーのクエリに最も関連する情報が検索結果の中でどの位置にあるかを見て、その位置の逆数(1を位置で割った値)を取り、それらの平均を計算します。
- 例:もしユーザーのクエリに最も関連する情報が検索結果の1位にあれば、その逆数は1/1 = 1です。3位にあれば、1/3 = 0.33です。これを平均するとMRRの値が求められます。
NDCG(Normalized Discounted Cumulative Gain)
- 定義:検索結果全体の品質を、関連情報の「関連度」に基づいて重み付けし、その情報がどれだけ上位にあるかによってさらに重み付けして計算します。
- 例:関連度の高い情報が上位にあるほど良いとされ、その重み付けされたスコアを合計し、理想的な場合のスコアで正規化します。例えば、最も関連度の高い情報が1位、次に高い情報が2位にあるのが理想的な順序になります。
実験方法
目的
前ブログでは目視で質問文に対してどの箇所がマッチしているのか、または検索結果の変化から考察を進めました。
今回は埋め込みモデルを使って検索精度を定量的に分析をします。
モデルは以下の5つを使用します。
- amazon.titan-embed-text-v1
- amazon.titan-embed-text-v2
- text-embedding-ada-002
- text-embedding-3-small
- text-embedding-3-large
手法
モデル別に検索されたドキュメント上位7位のスコアを比較します。
ranxの使い方
ranxバージョン0.3.5にはpythonバージョン3.8以上が必要になります。
pip install ranx
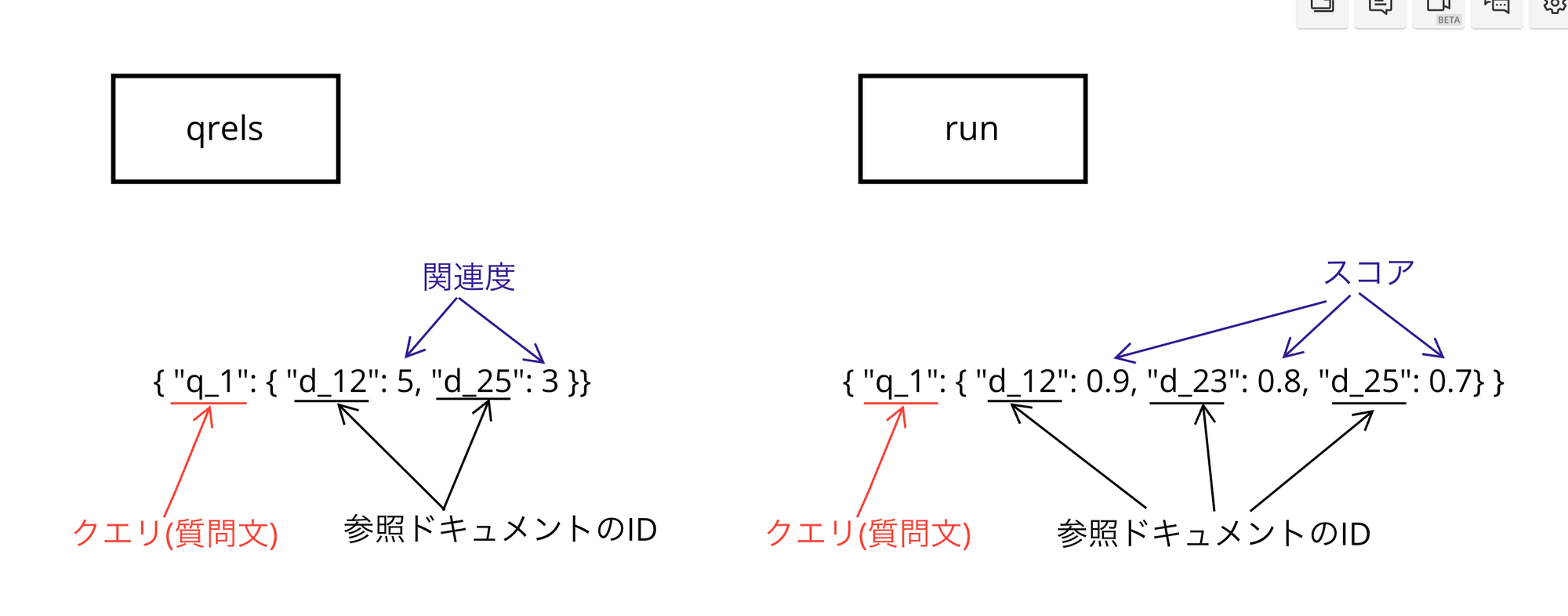
qrelsとrunの説明
from ranx import Qrels, Run
qrels_dict = { "q_1": { "d_12": 5, "d_25": 3 } }
run_dict = {"q_1": { "d_12": 0.9, "d_23": 0.8, "d_25": 0.7,"d_36": 0.6, "d_32": 0.5, "d_35": 0.4 },
"q_2": { "d_12": 0.9, "d_11": 0.8, "d_25": 0.7,"d_36": 0.6, "d_22": 0.5, "d_35": 0.4 } }
qrels = Qrels(qrels_dict)
run = Run(run_dict)
Qrels:
各クエリに対するドキュメントの正解ラベル(関連度)を保持します。ここでは、クエリ "q_1" に対して、ドキュメント "d_12" が関連度5、"d_25" が関連度3であることを示しています。
Qrels オブジェクトで指定されたもので、各ドキュメントに対するスコア(関連性の度合い)が辞書形式で格納されています。Qrels 辞書では、キーがクエリ、値がそれぞれのドキュメントIDとそのクエリに対する関連性のスコアの辞書です。
Run:
検索システムが返したランキングのスコア結果を保持します。クエリ "q_1" に対して、ドキュメント "d_12" のスコアが0.9、"d_23" のスコアが0.8 などと設定されています。
ranx ライブラリでは、"関連"していると判断する条件は、クエリとドキュメントのrunのスコア によって決まります。
ranx で「関連している」と判断する基本的な条件は以下の通りです:
- ドキュメントは、
Qrelsで指定されたクエリに対して、ゼロより大きいスコアを持っていれば、「関連している」と判定します。これはドキュメントがクエリに対して何らかの関連性があると評価されていることを意味します。 - たとえば、
qrels_dictでは、"q_1"クエリに対して、"d_12"ドキュメントのスコアが5、"d_25"のスコアが3となっています。よって、これらのドキュメントはクエリ"q_1"に対して関連していると判断されます。対して、"q_1"クエリに対して、”d_1”というドキュメントのスコアが格納されていないため関連度スコアがないため、d_1は関連度がないと判定します。
図解
導入
データセット
データセットは尼崎市質問掲示板のFAQデータセットを使用しました。クエリに対し、クエリと複数あるアンサー関連度順に格納されている検索データセットの正解データとしています。
データはqrelsとrunの辞書形式でデータ整形をしました。
!curl https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip > data/localgovfaq.zip
!unzip data/localgovfaq.zip -d data/localgovfaq
実装
import pandas as pd
import os
from dotenv import load_dotenv
import pandas as pd
import llama_index
from llama_index.core import (
VectorStoreIndex,
Document,
)
from llama_index.embeddings.bedrock import BedrockEmbedding
from llama_index.embeddings.openai import OpenAIEmbedding
from ranx import Qrels, Run, evaluate
# .envファイルから環境変数を読み込む
load_dotenv()
# 環境変数から必要な情報を取得
aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
region = os.getenv("AWS_DEFAULT_REGION", None)
openai_api_key = os.getenv("OPENAI_API_KEY")
# クエリデータとドキュメント関連度のデータを読み込む
testset_path = "localgovfaq/testset.txt"
testset_df = pd.read_csv(testset_path, sep='\t', header=None).fillna("None")
testset_df.columns = ['Query', 'A_ID', 'B_ID', 'C_ID']
# QAペアのIDとQAの回答が含まれています
answers_path = "localgovfaq/qas/answers_in_Amagasaki.txt"
answers_df = pd.read_csv(answers_path, sep='\t', header=None, names=['ID', 'Answer'])
answers = answers_df["Answer"].values.tolist()
# ranx用に指定されたフォーマットの辞書に変換
# qrelsとは(Quality Relevance)は、情報検索システムの評価
level_to_int = {'A': 3, 'B': 2, 'C': 1}
qrels_dict = {}
for index, row in testset_df.iterrows():
sub_dict = {}
for level in level_to_int.keys():
id_column = f'{level}_ID'
doc_ids = row[id_column].split(' ')
level_to_int = {'A': 3, 'B': 2, 'C': 1}
sub_dict.update({f'd_{doc_id}': level_to_int[level] for doc_id in doc_ids if doc_id != 'None'})
qrels_dict[f'q_{index+1}'] = sub_dict
# Run作成
# Runとは、特定の検索システムやアルゴリズムによって生成された結果のセット
def run_test(base_retriever):
run_dict = {}
for i, query in enumerate(testset_df["Query"].values.tolist(), start=1):
docs = base_retriever.get_relevant_documents(query)
run_dict[f'q_{i}'] = {}
for j, doc in enumerate(docs):
doc_id = doc.metadata["id"]
score = len(docs) - j
run_dict[f'q_{i}']= run_dict[f'q_{i}'] | {f"d_{doc_id}": score}
return run_dict
# Titanモデルのパラメータを設定します
model_kwargs_titan = {
"stopSequences": [], # 停止シーケンスを設定します
"temperature":0.0, # temperatureを設定します
"topP":0.5 # topPを設定します
}
# OpenAIモデルのパラメータを設定します
model_kwargs_openai = {
"stopSequences": [], # 停止シーケンスを設定します
"temperature": 0.0, # temperatureを設定します
"topP": 0.5 # topPを設定します
}
# 各embeddingモデルを使って、nodeからインデックス作成
model_dict = {
"titan_v1": BedrockEmbedding().from_credentials(aws_profile=None, model_name='amazon.titan-embed-text-v1'),
"titan_v2": BedrockEmbedding().from_credentials(aws_profile=None, model_name='amazon.titan-embed-text-v2'),
"openai_002": OpenAIEmbedding(model="text-embedding-ada-002", api_key=openai_api_key),
"openai_003_small": OpenAIEmbedding(model="text-embedding-3-small", api_key=openai_api_key),
"openai_003_large": OpenAIEmbedding(model="text-embedding-3-large", api_key=openai_api_key)
}
# Docsの作成
docs = [Document(text=answer, metadata={"id": str(i)}) for i, answer in enumerate(answers_df['Answer'].values.tolist())]
# クエリを取得して検索を行い、結果を辞書に格納する関数
def run_search_and_store_results(testset_df, index, k):
run_dict = {}
for i, query in enumerate(testset_df["Query"].values.tolist(), start=1):
# 検索実行
base_retriever = index.as_retriever(similarity_top_k=k)
docs = base_retriever.retrieve(query) # llama-index retrieveメソッドを使用
# 結果を辞書に格納
run_dict[f'q_{i}'] = {}
for j, doc in enumerate(docs):
doc_id = doc.metadata["id"]
score = len(docs) - j # スコアはドキュメントの位置に基づく
run_dict[f'q_{i}'] = run_dict[f'q_{i}'] | {f"d_{doc_id}": score}
return run_dict
#kはトップ検索結果の順位
top_k_values = [3, 5, 7, 10]
for model_name, embed_model in model_dict.items():
# 選択したモデルを使用してインデックスを作成
index = VectorStoreIndex(docs, embed_model=embed_model)
for k in top_k_values:
run_dict = run_search_and_store_results(testset_df, index, k)
qrels = Qrels(qrels_dict)
run_large = Run(run_dict)
print(f"Model: {model_name}, Top K: {k}")
print(evaluate(qrels, run_large, [f"hit_rate@{k}", f"mrr@{k}", f"ndcg@{k}"]))
結果
Top 7件
| Model | 上位7件 | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v1 | 7 | 0.6352 | 0.4378 | 0.3395 |
| amazon.titan-embed-text-v2 | 7 | 0.6352 | 0.4378 | 0.3395 |
| text-embedding-ada-002 | 7 | 0.7933 | 0.6023 | 0.4944 |
| text-embedding-3-small | 7 | 0.7653 | 0.5642 | 0.4614 |
| text-embedding-3-large | 7 | 0.8622 | 0.6595 | 0.5682 |
- amazon.titan-embed-text-v1とv2よりOpenAIのモデルがスコアが高かった
- text-embedding-3-largeが一番スコアが高かった
- text-embedding-3-smallよりtext-embedding-ada-002がスコアが高かった
感想(考察)
今回のranxを用いた定量的な分析では、用意した各モデルの検索精度を比較しました。今回のデータでは、OpenAIのtext-embedding-3-largeモデルがHit Rate、MRR、NDCGのすべての評価指標で最も高い検索精度を示しました。これにより、このモデルがユーザーのクエリに対して最も関連性の高いドキュメントが検索されることがわかりました。
この結果からモデルのよって検索性能が大きく変わるため、検索精度を向上させるためには、対象とするデータに応じて適した埋め込みモデルを選択することが重要です。
今後、実データを用いてqrelsとrunを作成できればと思います。しかしテスト・正解データの整備や解析環境を整えることが課題になります。
まとめ
定量的に検索精度を算出することができました。こうした評価手法をつかうことで、より良い検索精度のモデルを選択することができます。
参考
補足
モデル毎と参照するドキュメント上位3,5,10件毎のスコアをまとめました。
モデル毎
amazon.titan-embed-text-v1
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v1 | 3 | 0.5267 | 0.4164 | 0.3052 |
| amazon.titan-embed-text-v1 | 5 | 0.5880 | 0.4304 | 0.3216 |
| amazon.titan-embed-text-v1 | 7 | 0.6352 | 0.4378 | 0.3395 |
| amazon.titan-embed-text-v1 | 10 | 0.6658 | 0.4413 | 0.3592 |
amazon.titan-embed-text-v2
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v2 | 3 | 0.5267 | 0.4164 | 0.3052 |
| amazon.titan-embed-text-v2 | 5 | 0.5880 | 0.4304 | 0.3216 |
| amazon.titan-embed-text-v2 | 7 | 0.6352 | 0.4378 | 0.3395 |
| amazon.titan-embed-text-v2 | 10 | 0.6658 | 0.4413 | 0.3592 |
text-embedding-ada-002
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| text-embedding-ada-002 | 3 | 0.6823 | 0.5801 | 0.4423 |
| text-embedding-ada-002 | 5 | 0.7487 | 0.5954 | 0.4716 |
| text-embedding-ada-002 | 7 | 0.7933 | 0.6023 | 0.4944 |
| text-embedding-ada-002 | 10 | 0.8367 | 0.6070 | 0.5194 |
text-embedding-3-small
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| text-embedding-3-small | 3 | 0.6415 | 0.5391 | 0.4089 |
| text-embedding-3-small | 5 | 0.7193 | 0.5571 | 0.4372 |
| text-embedding-3-small | 7 | 0.7653 | 0.5642 | 0.4614 |
| text-embedding-3-small | 10 | 0.8010 | 0.5683 | 0.4851 |
text-embedding-3-large
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| text-embedding-3-large | 3 | 0.7385 | 0.6341 | 0.5095 |
| text-embedding-3-large | 5 | 0.8048 | 0.6501 | 0.5387 |
| text-embedding-3-large | 7 | 0.8622 | 0.6595 | 0.5682 |
| text-embedding-3-large | 10 | 0.8979 | 0.6638 | 0.5918 |
Top N件ごと
Top 3件
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v1 | 3 | 0.5267 | 0.4164 | 0.3052 |
| amazon.titan-embed-text-v2 | 3 | 0.5267 | 0.4164 | 0.3052 |
| text-embedding-ada-002 | 3 | 0.6823 | 0.5801 | 0.4423 |
| text-embedding-3-small | 3 | 0.6415 | 0.5391 | 0.4089 |
| text-embedding-3-large | 3 | 0.7385 | 0.6341 | 0.5095 |
Top 5件
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v1 | 5 | 0.5880 | 0.4304 | 0.3216 |
| amazon.titan-embed-text-v2 | 5 | 0.5880 | 0.4304 | 0.3216 |
| text-embedding-ada-002 | 5 | 0.7487 | 0.5954 | 0.4716 |
| text-embedding-3-small | 5 | 0.7193 | 0.5571 | 0.4372 |
| text-embedding-3-large | 5 | 0.8048 | 0.6501 | 0.5387 |
Top 10件
| Model | Top K | Hit Rate | MRR | NDCG |
|---|---|---|---|---|
| amazon.titan-embed-text-v1 | 10 | 0.6658 | 0.4413 | 0.3592 |
| amazon.titan-embed-text-v2 | 10 | 0.6658 | 0.4413 | 0.3592 |
| text-embedding-ada-002 | 10 | 0.8367 | 0.607 | 0.5194 |
| text-embedding-3-small | 10 | 0.8010 | 0.5683 | 0.4851 |
| text-embedding-3-large | 10 | 0.8979 | 0.6638 | 0.5918 |









